
diff options
| author | Andrew Maguire <andrewm4894@gmail.com> | 2022-06-25 16:12:18 +0100 |
|---|---|---|
| committer | GitHub <noreply@github.com> | 2022-06-25 16:12:18 +0100 |
| commit | d40cb1e446b2a25ea9f14502b3aa8e33825889ba (patch) | |
| tree | a7d77c40fc46af8755ebb473f4204619cd565b42 /ml/README.md | |
| parent | 1d8992a7d67851cf5403e320ad737ec3e0590b97 (diff) | |
make configuration example clearer (#13182)
make ml configuration example cleare
Diffstat (limited to 'ml/README.md')
| -rw-r--r-- | ml/README.md | 37 |
1 files changed, 14 insertions, 23 deletions
diff --git a/ml/README.md b/ml/README.md index c752fc8521..385d305fe9 100644 --- a/ml/README.md +++ b/ml/README.md @@ -183,43 +183,34 @@ Below is a list of all the available configuration params and their default valu If you would like to run ML on a parent instead of at the edge, some configuration options are illustrated below. -This example assumes 3 child nodes [streaming](https://learn.netdata.cloud/docs/agent/streaming) to 1 parent node and illustrates the main ways you might want to configure running ml for the children on the parent, running ML on the children themselves, or even a mix of approaches. +This example assumes 3 child nodes [streaming](https://learn.netdata.cloud/docs/agent/streaming) to 1 parent node and illustrates the main ways you might want to configure running ML for the children on the parent, running ML on the children themselves, or even a mix of approaches. 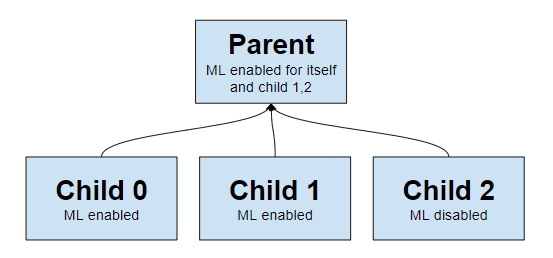 ``` -# parent will run ml for itself and child 1,2. -# child 0 will run its own ml at the edge and just stream its ml charts to parent. -# child 1 will run its own ml at the edge, even though parent will also run ml for it, a bit wasteful potentially to run ml in both places but is possible. -# child 2 will not run ml at the edge, it will be run in the parent only. +# parent will run ML for itself and child 1,2, it will skip running ML for child 0. +# child 0 will run its own ML at the edge. +# child 1 will run its own ML at the edge, even though parent will also run ML for it, a bit wasteful potentially to run ML in both places but is possible (Netdata Cloud will essentially average any overlapping models). +# child 2 will not run ML at the edge, it will be run in the parent only. -# parent-ml-ml-stress-0 -# run ml on all hosts apart from child-ml-ml-stress-0 +# parent-ml-enabled +# run ML on all hosts apart from child-ml-enabled [ml] enabled = yes - minimum num samples to train = 900 - train every = 900 - charts to skip from training = !* - hosts to skip from training = child-ml-ml-stress-0 + hosts to skip from training = child-0-ml-enabled -# child-ml-ml-stress-0 -# run ml on child-ml-ml-stress-0 and stream ml charts to parent +# child-0-ml-enabled +# run ML on child-0-ml-enabled [ml] enabled = yes - minimum num samples to train = 900 - train every = 900 - stream anomaly detection charts = yes -# child-ml-ml-stress-1 -# run ml on child-ml-ml-stress-1 and stream ml charts to parent +# child-1-ml-enabled +# run ML on child-1-ml-enabled [ml] enabled = yes - minimum num samples to train = 900 - train every = 900 - stream anomaly detection charts = yes -# child-ml-ml-stress-2 -# don't run ml on child-ml-ml-stress-2, it will instead run on parent-ml-ml-stress-0 +# child-2-ml-disabled +# do not run ML on child-2-ml-disabled [ml] enabled = no ``` |