
diff options
| author | Joel Hans <joel@netdata.cloud> | 2020-09-29 10:57:52 -0700 |
|---|---|---|
| committer | GitHub <noreply@github.com> | 2020-09-29 10:57:52 -0700 |
| commit | 61d7e23eed0503bf591274df70713970213b5c7f (patch) | |
| tree | 125879ff5f780c2937ee206fc510d89e9a91a868 /docs/monitor | |
| parent | e3b04fb39a06991d9a2deed0488044dd7d340e3f (diff) | |
Add docsv2 project to master branch (#10000)
* Add overview docs to docsv2 project
* Add quickstart docs to docsv2 project (#9865)
* Init quickstart docs
* Begin work on quickstart guides
* Finish quickstart drafts
* Tweaks to both quickstarts
* Add titles
* Copyedit pass to both docs
* Fixes for Amy and Jen
* Add Get doc to docsv2 project (#9854)
* Init get file
* Add some links
* Change h2 to h1
* Rephrase
* Add configure docs to docsv2 project (#9878)
* Add overview docs to docsv2 project (#9849)
* Init files
* Add drafts of what and why
* Finish initial drafts
* Fix edit URL
* Copyedit pass
* Finish initial drafts of configure docs
* Copyedit all docs
* Fixes for Amy
* Fixes for Jen
* Add collect docs to the docsv2 project (#9932)
* Init files
* Finish first two collect docs
* Finish drafts of collect docs
* Copyedit pass
* Fixes for Amy
* Fix for Jen
* Add visualize docs to the docsv2 project (#9943)
* Add visualize docs
* Copyedits and cleanup
* New images and features
* Copyedit pass and cleanup
* Missing word
* Fixes for Jen
* Add monitor docs to docsv2 project (#9949)
* Finish drafts of monitor docs
* Copyedit pass
* Remove whitespace
* Fixes for Jen
* Add store docs to docsv2 project (#9969)
* Finalize store documents
* Fix import path
* Finishing edit section
* Copyedit pass
* Add export docs to docsv2 project (#9986)
* Add install and claim videos to Get doc
* Finish drafts of exporting docs plus other tweaks
* Init new exporting READMEs
* Copyedit pass and new links
* Fixes for Amy, Vlad, Jen
* Fix links in docsv2 project (#9993)
* Fix links
* Fix a bunch of links ahead of export merge
* Fix additional links
* Fix links, nuke what-is-netdata
* Fixing a few last links
* Improve product images in overview
* Remove extra paren
* Quick tweaks for Jen
* Fixes for Jen
* Access fix
* Remove extra word
Diffstat (limited to 'docs/monitor')
| -rw-r--r-- | docs/monitor/configure-alarms.md | 144 | ||||
| -rw-r--r-- | docs/monitor/enable-notifications.md | 126 | ||||
| -rw-r--r-- | docs/monitor/view-active-alarms.md | 76 |
3 files changed, 346 insertions, 0 deletions
diff --git a/docs/monitor/configure-alarms.md b/docs/monitor/configure-alarms.md new file mode 100644 index 0000000000..a11ba32a27 --- /dev/null +++ b/docs/monitor/configure-alarms.md @@ -0,0 +1,144 @@ +<!-- +title: "Configure health alarms" +description: "Netdata's health monitoring watchdog is incredibly adaptable to your infrastructure's unique needs, with configurable health alarms." +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/monitor/configure-alarms.md +--> + +# Configure health alarms + +Netdata's health watchdog is highly configurable, with support for dynamic thresholds, hysteresis, alarm templates, and +more. You can tweak any of the existing alarms based on your infrastructure's topology or specific monitoring needs, or +create new entities. + +You can use health alarms in conjunction with any of Netdata's [collectors](/docs/collect/how-collectors-work.md) (see +the [supported collector list](/collectors/COLLECTORS.md)) to monitor the health of your systems, containers, and +applications in real time. + +While you can see active alarms both on the local dashboard and Netdata Cloud, all health alarms are configured _per +node_ via individual Netdata Agents. If you want to deploy a new alarm across your +[infrastructure](/docs/quickstart/infrastructure.md), you must configure each node with the same health configuration +files. + +## Edit health configuration files + +All of Netdata's [health configuration files](/health/REFERENCE.md#health-configuration-files) are in Netdata's config +directory, inside the `health.d/` directory. Use Netdata's `edit-config` script to make changes to any of these files. + +For example, to edit the `cpu.conf` health configuration file, run: + +```bash +sudo ./edit-config health.d/cpu.conf +``` + +Each health configuration file contains one or more health _entities_, which always begin with `alarm:` or `template:`. +For example, here is the first health entity in `health.d/cpu.conf`: + +```yaml +template: 10min_cpu_usage + on: system.cpu + os: linux + hosts: * + lookup: average -10m unaligned of user,system,softirq,irq,guest + units: % + every: 1m + warn: $this > (($status >= $WARNING) ? (75) : (85)) + crit: $this > (($status == $CRITICAL) ? (85) : (95)) + delay: down 15m multiplier 1.5 max 1h + info: average cpu utilization for the last 10 minutes (excluding iowait, nice and steal) + to: sysadmin +``` + +To tune this alarm to trigger warning and critical alarms at a lower CPU utilization, change the `warn` and `crit` lines +to the values of your choosing. For example: + +```yaml + warn: $this > (($status >= $WARNING) ? (60) : (75)) + crit: $this > (($status == $CRITICAL) ? (75) : (85)) +``` + +Save the file and [reload Netdata's health configuration](#reload-health-configuration) to make your changes live. + +### Silence an individual alarm + +Many Netdata users don't need all the default alarms enabled. Instead of disabling any given alarm, or even _all_ +alarms, you can silence individual alarms by changing one line in a given health entity. + +To silence any single alarm, change the `to:` line to `silent`. + +```yaml + to: silent +``` + +## Write a new health entity + +While tuning existing alarms may work in some cases, you may need to write entirely new health entities based on how +your systems and applications work. + +Read Netdata's [health reference](/health/REFERENCE.md#health-entity-reference) for a full listing of the format, +syntax, and functionality of health entities. + +To write a new health entity, use `edit-config` to create a new file inside of the `health.d/` directory. + +```bash +sudo ./edit-config health.d/example.conf +``` + +For example, here is a health entity that triggers an alarm when a node's RAM usage rises above 80%: + +```yaml + alarm: ram_usage + on: system.ram +lookup: average -1m percentage of used + units: % + every: 1m + warn: $this > 80 + crit: $this > 90 + info: The percentage of RAM being used by the system. +``` + +Let's look into each of the lines to see how they create a working health entity. + +- `alarm`: The name for your new entity. The name needs to follow these requirements: + - Any alphabet letter or number. + - The symbols `.` and `_`. + - Cannot be `chart name`, `dimension name`, `family name`, or `chart variable names`. +- `on`: Which chart the entity listens to. +- `lookup`: Which metrics the alarm monitors, the duration of time to monitor, and how to process the metrics into a + usable format. + - `average`: Calculate the average of all the metrics collected. + - `-1m`: Use metrics from 1 minute ago until now to calculate that average. + - `percentage`: Clarify that we're calculating a percentage of RAM usage. + - `of used`: Specify which dimension (`used`) on the `system.ram` chart you want to monitor with this entity. +- `units`: Use percentages rather than absolute units. +- `every`: How often to perform the `lookup` calculation to decide whether or not to trigger this alarm. +- `warn`/`crit`: The value at which Netdata should trigger a warning or critical alarm. This example uses simple + syntax, but most pre-configured health entities use + [hysteresis](/health/REFERENCE.md#special-usage-of-the-conditional-operator) to avoid superfluous notifications. +- `info`: A description of the alarm, which will appear in the dashboard and notifications. + +In human-readable format: + +> This health entity, named **ram_usage**, watches the **system.ram** chart. It looks up the last **1 minute** of +> metrics from the **used** dimension and calculates the **average** of all those metrics in a **percentage** format, +> using a **% unit**. The entity performs this lookup **every minute**. +> +> If the average RAM usage percentage over the last 1 minute is **more than 80%**, the entity triggers a warning alarm. +> If the usage is **more than 90%**, the entity triggers a critical alarm. + +When you finish writing this new health entity, [reload Netdata's health configuration](#reload-health-configuration) to +see it live on the local dashboard or Netdata Cloud. + +## Reload health configuration + +To make any changes to your health configuration live, you must reload Netdata's health monitoring system. To do that +without restarting all of Netdata, run `netdatacli reload-health` or `killall -USR2 netdata`. + +## What's next? + +With your health entities configured properly, it's time to [enable +notifications](/docs/monitor/enable-notifications.md) to get notified whenever a node reaches a warning or critical +state. + +To build complex, dynamic alarms, read our guide on [dimension templates](/docs/guides/monitor/dimension-templates.md). + +[](<>) diff --git a/docs/monitor/enable-notifications.md b/docs/monitor/enable-notifications.md new file mode 100644 index 0000000000..554c96e0c4 --- /dev/null +++ b/docs/monitor/enable-notifications.md @@ -0,0 +1,126 @@ +<!-- +title: "Enable notifications" +description: "Send Netdata's alerts to platforms like email, Slack, PagerDuty, Twilio, and more to enable incident response and faster resolution." +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/monitor/enable-notifications.md +--> + +# Enable notifications + +Netdata comes with a notification system that supports more than a dozen services, such as email, Slack, PagerDuty, +Twilio, Amazon SNS, Discord, and much more. You can enable as many platforms as you want, and configure them to match +your organization's needs with features like role-based notifications. + +To see all the supported platforms, visit our [notifications](/health/notifications/README.md) doc. + +This doc covers enabling email and Slack notifications, but the same process applies to enabling any other notification +platform. + +## Enable email notifications + +To use email notifications, you need [`sendmail`](http://www.postfix.org/sendmail.1.html) or an equivalent installed on +your system. + +Edit the `health_alarm_notify.conf` file, which resides in your Netdata [config +directory](/docs/configure/nodes.md#netdata-config-directory). + +```bash +sudo ./edit-config health_alarm_notify.conf +``` + +Look for the following lines: + +```conf +# if a role recipient is not configured, an email will be sent to: +DEFAULT_RECIPIENT_EMAIL="root" +# to receive only critical alarms, set it to "root|critical" +``` + +Change the value of `DEFAULT_RECIPIENT_EMAIL` to the email address at which you'd like to receive notifications. + +```conf +# if a role recipient is not configured, an email will be sent to: +DEFAULT_RECIPIENT_EMAIL="me@example.com" +# to receive only critical alarms, set it to "root|critical" +``` + +Test email notifications system by first becoming the Netdata user and then asking Netdata to send a test alarm: + +```bash +sudo su -s /bin/bash netdata +/usr/libexec/netdata/plugins.d/alarm-notify.sh test +``` + +You should see output similar to this: + +```bash +# SENDING TEST WARNING ALARM TO ROLE: sysadmin +2019-10-17 18:23:38: alarm-notify.sh: INFO: sent email notification for: hostname test.chart.test_alarm is WARNING to 'me@example.com' +# OK + +# SENDING TEST CRITICAL ALARM TO ROLE: sysadmin +2019-10-17 18:23:38: alarm-notify.sh: INFO: sent email notification for: hostname test.chart.test_alarm is CRITICAL to 'me@example.com' +# OK + +# SENDING TEST CLEAR ALARM TO ROLE: sysadmin +2019-10-17 18:23:39: alarm-notify.sh: INFO: sent email notification for: hostname test.chart.test_alarm is CLEAR to 'me@example.com' +# OK +``` + +Check your email. You should receive three separate emails for each health status change: `WARNING`, `CRITICAL`, and +`CLEAR`. + +See the [email notifications](/health/notifications/email/README.md) doc for more options and information. + +## Enable Slack notifications + +If you're one of the many who spend their workday getting pinged with GIFs by your colleagues, why not add Netdata +notifications to the mix? It's a great way to immediately see, collaborate around, and respond to anomalies in your +infrastructure. + +To get Slack notifications working, you first need to add an [incoming +webhook](https://slack.com/apps/A0F7XDUAZ-incoming-webhooks) to the channel of your choice. Click the green **Add to +Slack** button, choose the channel, and click the **Add Incoming WebHooks Integration** button. + +On the following page, you'll receive a **Webhook URL**. That's what you'll need to configure Netdata, so keep it handy. + +Time to dive back into your `health_alarm_notify.conf` file: + +```bash +sudo ./edit-config health_alarm_notify.conf +``` + +Look for the `SLACK_WEBHOOK_URL=" "` line and add the incoming webhook URL you got from Slack: + +```conf +SLACK_WEBHOOK_URL="https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/XXXXXXXXXXXX" +``` + +A few lines down, edit the `DEFAULT_RECIPIENT_SLACK` line to contain a single hash `#` character. This instructs Netdata +to send a notification to the channel you configured with the incoming webhook. + +```conf +DEFAULT_RECIPIENT_SLACK="#" +``` + +Time to test the notifications again: + +```bash +sudo su -s /bin/bash netdata +/usr/libexec/netdata/plugins.d/alarm-notify.sh test +``` + +You should receive three notifications in your Slack channel for each health status change: `WARNING`, `CRITICAL`, and +`CLEAR`. + +See the [Slack notifications](/health/notifications/slack/README.md) doc for more options and information. + +## What's next? + +Learn more about Netdata's notifications system in the [notifications](/health/notifications/README.md) docs. + +Now that you have health entities configured to your infrastructure's needs, and notifications to inform you of +anomalies, you have everything you need to monitor the health of your infrastructure. To make your dashboards most +useful during root cause analysis, you can use Netdata's [distributed data +architecture](/docs/store/distributed-data-architecture.md) for the best-in-class performance and scalability. + +[](<>) diff --git a/docs/monitor/view-active-alarms.md b/docs/monitor/view-active-alarms.md new file mode 100644 index 0000000000..81460095fe --- /dev/null +++ b/docs/monitor/view-active-alarms.md @@ -0,0 +1,76 @@ +<!-- +title: "View active health alarms" +description: "View active alarms and their rich data to discover and resolve anomalies and performance issues across your infrastructure." +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/monitor/view-active-alarms.md +--> + +# View active health alarms + +Every Netdata Agent comes with hundreds of pre-installed health alarms designed to notify you when an anomaly or +performance issue affects your node or the applications it runs. + +As soon as you launch a Netdata Agent and [claim it](/docs/get/README.md#claim-your-node-on-netdata-cloud), you can view +active alarms in both the local dashboard and Netdata Cloud. + +## View active alarms in Netdata Cloud + +You can see active alarms from any node in your infrastructure in two ways: Click on the bell 🔔 icon in the top +navigation, or click on the first column of any node's row in Nodes. This column's color changes based on the node's +health status: gray is `CLEAR`, yellow is `WARNING`, and red is `CRITICAL`. + +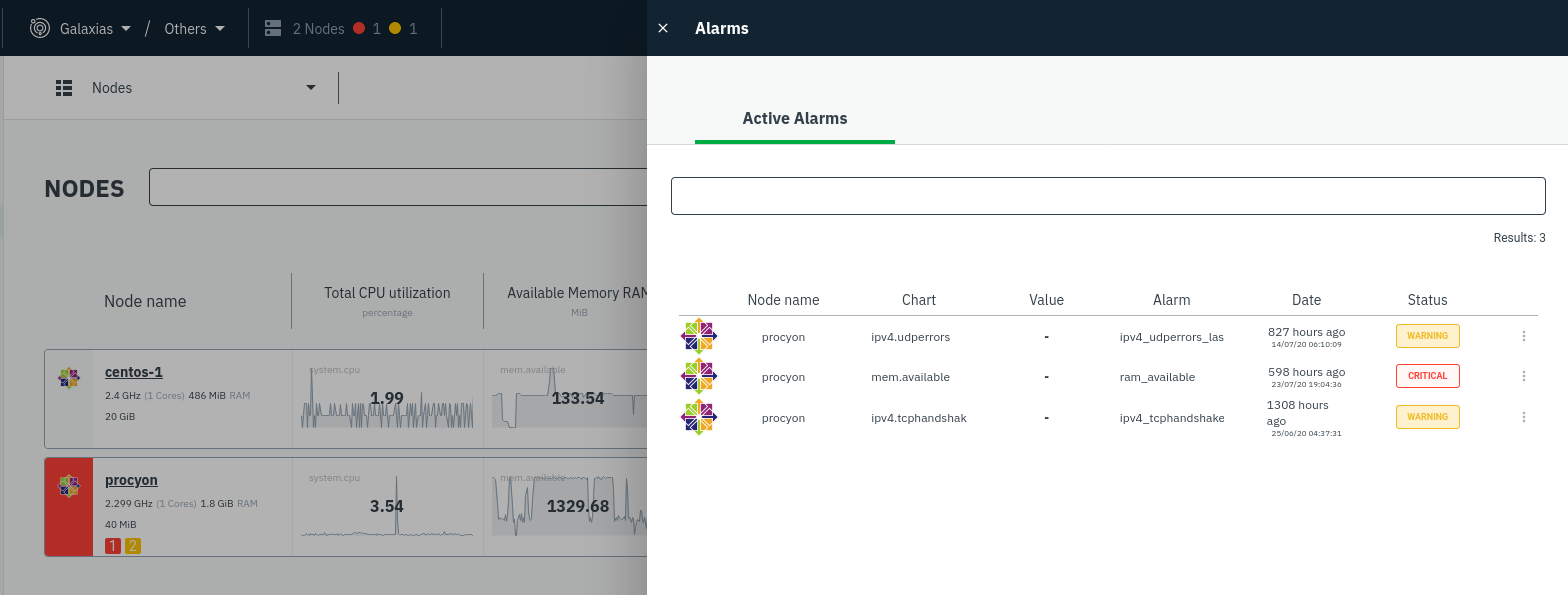 + +The Alarms panel lists all active alarms for nodes within that War Room, and tells you which chart triggered the alarm, +what that chart's current value is, the alarm that triggered it, and when the alarm status first began. + +You can use the input field in the Alarms panel to filter active alarms. You can sort by the node's name, alarm, status, +chart that triggered the alarm, or the operating system. Read more about the [filtering +syntax](/docs/visualize/view-all-nodes.md#filter-and-group-your-infrastructure) to build valuable filters for your +infrastructure. + +Click on the 3-dot icon (`⋮`) to view active alarm information or navigate directly to the offending chart in that +node's Cloud dashboard with the **Go to chart** button. + +The active alarm information gives you in-depth information about the alarm that's been triggered. You can see the +alarm's configuration, how it calculates warning or critical alarms, and which configuration file you could edit on that +node if you want to tweak or disable the alarm to better suit your needs. + +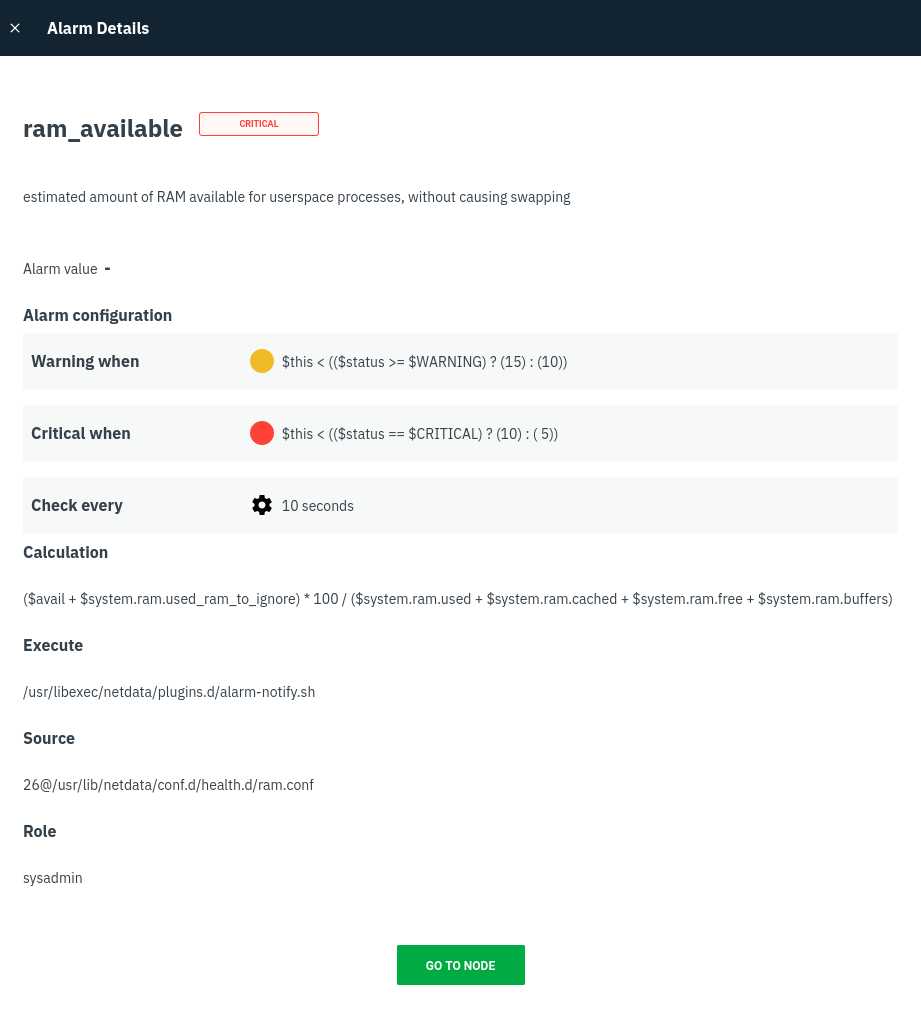 + +## View active alarms in the Netdata Agent + +Find the bell 🔔 icon in the top navigation to bring up a modal that shows currently raised alarms, all running alarms, +and the alarms log. Here is an example of a raised `system.cpu` alarm, followed by the full list and alarm log: + +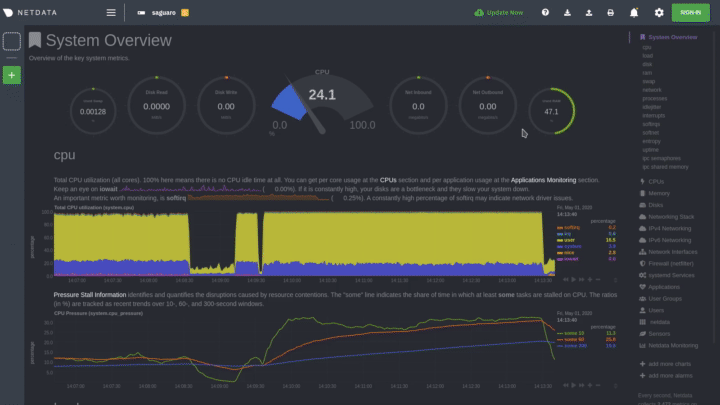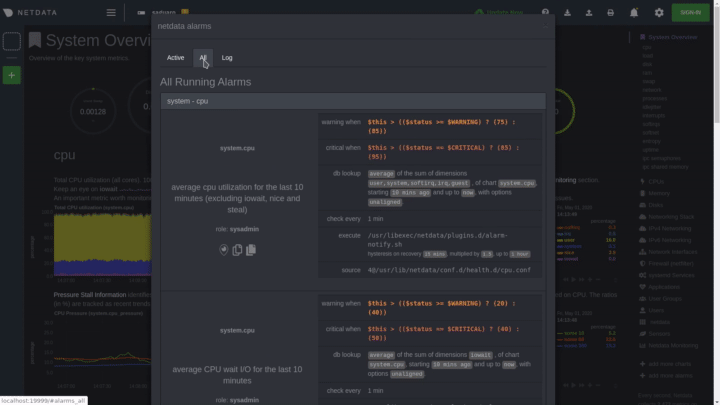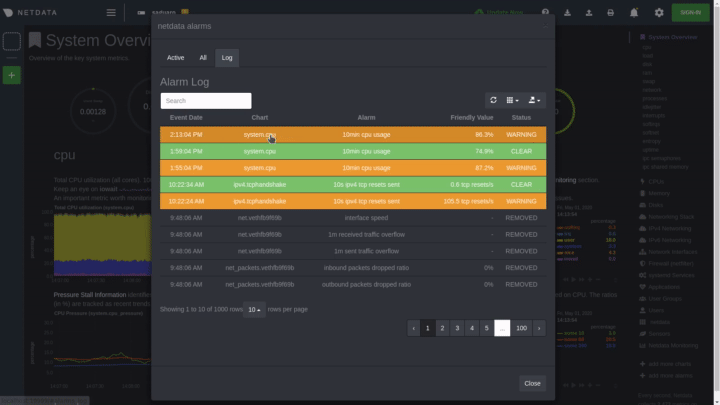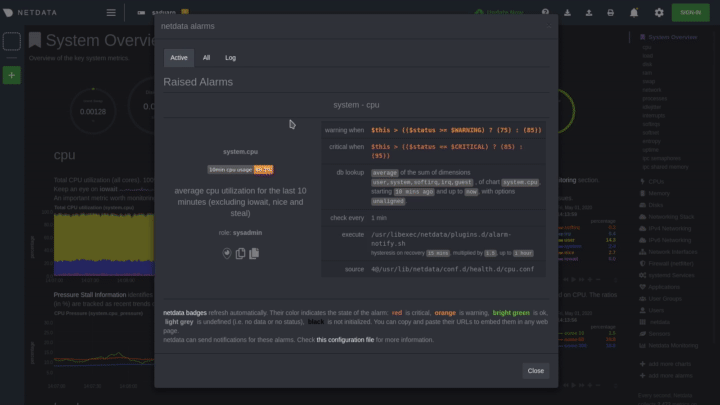 + +And a static screenshot of the raised CPU alarm: + + + +The alarm itself is named **system - cpu**, and its context is `system.cpu`. Beneath that is an auto-updating badge that +shows the latest value of the chart that triggered the alarm. + +With the three icons beneath that and the **role** designation, you can: + +1. Scroll to the chart associated with this raised alarm. +2. Copy a link to the badge to your clipboard. +3. Copy the code to embed the badge onto another web page using an `<embed>` element. + +The table on the right-hand side displays information about the health entity that triggered the alarm, which you can +use as a reference to [configure alarms](/docs/monitor/configure-alarms.md). + +## What's next? + +With the information that appears on Netdata Cloud and the local dashboard about active alarms, you can [configure +alarms](/docs/monitor/configure-alarms.md) to match your infrastructure's needs or your team's goals. + +If you're happy with the pre-configured alarms, skip ahead to [enable +notifications](/docs/monitor/enable-notifications.md) to instantly see alarms in email, Slack, PagerDuty, Twilio, and +many other platforms. + +[](<>) |